
Muchas empresas se adaptaron a un proceso “guiado por datos” para la toma operativa de decisiones. En el contexto VUCA, los datos pueden mejorar las decisiones, pero es necesario tener el procesador correcto para obtener el máximo de ellos. Muchos suponen que este procesador sea humano, el término “guiado por datos” incluso implica que la tutoría y el resumen de los datos sean hechos por personas, para que personas los procesen.
Pero, para sacar el máximo provecho del valor contenido en los datos, las empresas necesitan incluir la inteligencia artificial (IA) en sus flujos de trabajo y, de vez en cuando, alejarse del camino de nosotros, los humanos. Necesitamos evolucionar de flujos de trabajo guiados por datos a flujos de trabajo guiados por IA.
La diferencia entre “guiado por datos” y “guiado por IA” no es solo semántica.
Cada uno de estos términos refleja activos diferentes, el primero se centra en los datos y el segundo, en la capacidad de procesamiento. Los datos guardan los hallazgos que pueden permitir mejores decisiones; el procesamiento es la manera de extraer esos hallazgos y ejecutar acciones. Tanto los humanos como la IA son procesadores – con capacidades muy diferentes. Para comprender la mejor manera de aprovechar a cada uno, es útil examinar nuestra propia evolución biológica y la manera en que la toma de decisiones ha evolucionado en el mercado.
Hace unos 50 a 75 años atrás, el juicio humano era el procesador central de la toma de decisiones empresariales. Los profesionales se basaban en su intuición extremadamente afinada y desarrollada a lo largo de años de experiencia (y una cantidad relativamente minúscula de datos) en su área, para, por ejemplo, elegir al director de creación correcto para una campaña publicitaria, definir el nivel correcto de existencias a mantener o aprobar inversiones financieras correctas. La experiencia y el instinto eran la mayor parte de lo que estaba disponible para discernir entre bueno y malo, alto o bajo, arriesgados o seguros.
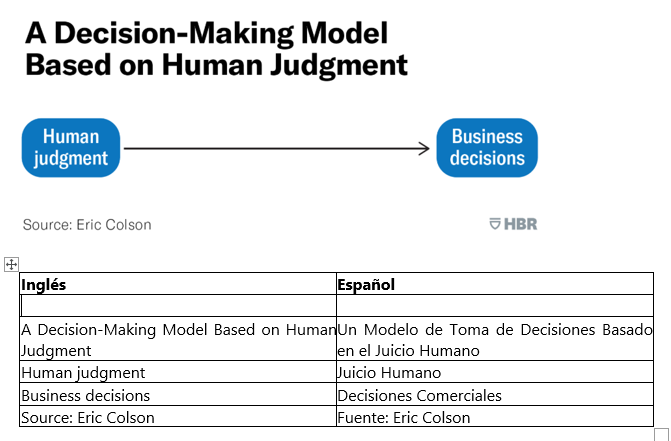
Tal vez todo era demasiado humano.
Nuestra intuición está lejos de ser un instrumento ideal de toma de decisiones. Nuestro cerebro está sometido a muchos sesgos cognitivos que perjudican nuestro juicio de maneras predecibles. Esto es resultado de centenas de millares de años de evolución en que, como cazadores-recolectores primitivos, desarrollamos un sistema de razonamiento basado en heurísticas simples – atajos o reglas empíricas que evitan el alto costo de procesar una gran cantidad de información. Esto permitía que decisiones rápidas y casi inconscientes nos libraran de situaciones potencialmente peligrosas. Sin embargo, “rápidas y casi inconscientes” no siempre significaba ideales, o incluso correctas.
Imagine un grupo de nuestros ancestros cazadores-recolectores aglomerados alrededor de una fogata, cuando repentinamente, escuchan un ruido de follaje, procedente de un arbusto próximo. Es necesario tomar una decisión del tipo “rápido y casi inconsciente”: deducir que el ruido es causado por un depredador peligroso y huir, o investigar y obtener más información para verificar si es una presa potencial – por ejemplo, un conejo, que puede proporcionar valiosos nutrientes. Nuestros ancestros más impulsivos – los que decidían huir – tenían un índice de supervivencia más alto que el de sus compañeros más curiosos. El costo de huir y perder un conejo es mucho menor que el de quedarse y correr el riesgo de morir a manos de un depredador. Con tal asimetría en los resultados, la evolución favorece la característica que tiene consecuencias menos costosas, aun cuando la corrección sea sacrificada. Por lo tanto, la característica que conduce a una toma de decisiones más impulsiva y a un menor procesamiento de las informaciones se vuelve más frecuente en la población descendente.
En el contexto moderno, la heurística de la supervivencia se transformó en una infinidad de sesgos cognitivos, precargados en nuestro cerebro heredado. Estos sesgos influyen en nuestro juicio y nuestra toma de decisiones de maneras que difieren de la objetividad racional. Damos más peso del que deberíamos a eventos vividos o recientes. Clasificamos sujetos groseramente, en estereotipos amplios que no explican suficientemente sus diferencias. Nos aferramos en la experiencia anterior, incluso cuando ésta es completamente irrelevante. Tendemos a conjurar explicaciones ilusorias para eventos que, la verdad, son solo ruidos aleatorios. Estas son solo algunas decenas de maneras en que los sesgos cognitivos perjudican el juicio humano y, durante décadas, fue el procesador central de la toma de decisiones empresariales. Sabemos ahora que contar sólo con la intuición humana es algo ineficiente, caprichoso, falible y limitador de la capacidad de la organización.
Toma de decisiones basada en datos
Aun siendo así, es bueno que existan los datos.
Hoy, dispositivos conectados capturan volúmenes impensables de datos: cada transacción, cada gesto de cliente, cada indicador micro y macroeconómico, todas las informaciones que pueden dar lugar a mejores decisiones. En respuesta a ese nuevo ambiente rico en datos, adaptamos nuestros flujos de trabajo. Las áreas de TI dan soporte al flujo de informaciones utilizando máquinas (banco de datos, sistemas de archivos distribuidos, etc., para reducir esos volúmenes de datos imposibles de administrar a resúmenes que puedan ser tratados por humanos. Enseguida, humanos procesan nuevamente esos resúmenes, utilizando herramientas como planillas, paneles de control y aplicativos de inteligencia analítica. Al final, los datos, altamente procesados y, a esta altura, reducidos a un volumen administrable, son presentados para la toma de decisiones. Este es el flujo de trabajo “guiado por datos”. El juicio humano permanece siendo el procesador central, pero ahora utiliza datos resumidos como nuevo input.
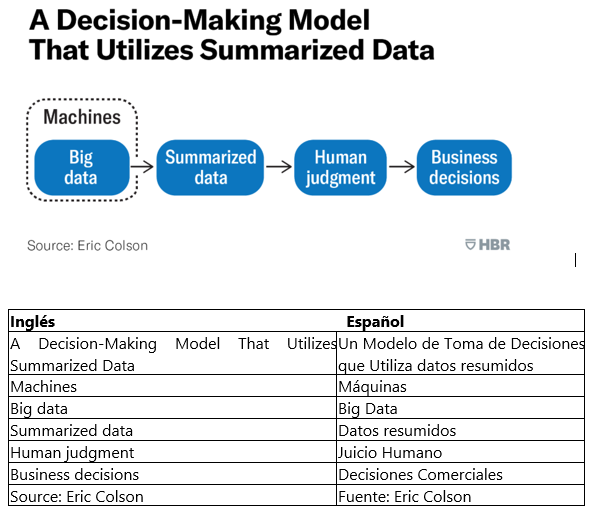
Si bien indudablemente es mejor tener a un ser humano como procesador central que depender únicamente de la intuición, todavía crea varias limitaciones.
1. No aprovechamos todos los datos.
Los datos resumidos pueden obscurecer muchos de los hallazgos, relaciones y patrones contenidos en el “data set” (conjunto de datos) original (de gran volumen). La reducción de los datos es necesaria para ajustar la capacidad de producción de los procesadores humanos, porque, por más hábiles que seamos para dirigir nuestro entorno, procesando fácilmente grandes cantidades de información ambiental, estamos notablemente limitados cuando se trata de procesar datos estructurados que se manifiestan en forma de millones o billones de registros.
La mente es capaz de manejar números referentes a ventas, y con precios medios de ventas elevados para el nivel regional, pero enfrenta dificultades o simplemente un “freno” cuando comenzamos a pensar en la distribución completa de los valores y, críticamente, las relaciones entre los elementos de datos- informaciones que se pierden para la buena toma de decisiones. (No se pretende sugerir que los resúmenes de datos no son útiles. Es Cierto que ellos son óptimos para proporcionar una visibilidad básica del negocio, pero agregan poco valor para su utilización en la toma de decisiones pues se pierde una gran parte en la preparación para el procesamiento por humanos). En otros casos, datos resumidos pueden ser simplemente engañosos. Factores de confusión pueden dar la apariencia de una relación positiva cuando, la verdad es que ocurre todo lo contrario (vea la paradoja de los Simpson y otros). Además de eso, una vez que los datos son agregados, puede ser imposible recuperar los factores contribuyentes para controlarlos adecuadamente. (La mejor práctica es utilizar estudios controlados aleatorios, es decir, pruebas A/B. Sin esta práctica, es posible que la IA ni siquiera pueda controlar adecuadamente los factores de confusión. En resumen, al usar humanos como procesadores de datos centrales, todavía sacrificamos la corrección para evitar el alto costo del procesamiento de datos humanos
2. Los datos no son suficientes para aislarnos del sesgo cognitivo.
Los resúmenes de datos son dirigidos por los humanos de una manera propensa a sesgos cognitivos. Orientamos la elaboración del resumen de una forma que nos es intuitiva y pedimos que los datos sean agregados en segmentos que nos parecen arquetipos representativos. A pesar de ellos, tendemos a clasificar sujetos groseramente, en estereotipos amplios que no explican suficientemente sus diferencias. Por ejemplo, podemos elevar los datos a atributos como la geografía, incluso cuando no hay diferencia perceptible de comportamiento entre las regiones.
Tambien se puede pensar en el resumen como una “granulación gruesa” de los datos; se trata de una aproximación gruesa de los datos. Por ejemplo, un atributo como geografía necesitar ser mantenido en un nivel regional en que relativamente pocos valores (esto es “este” x “oeste”). Lo que de verdad importa puede ser más refinado que eso – datos a nivel de ciudad, código postal, incluso calle. Eso es más difícil de agregar y resumir para ser procesado por el cerebro humano. Además, preferimos las relaciones simples entre los elementos; tendemos a pensar que las relaciones son lineales porque es más fácil procesarlas. La relación entre precio y ventas, penetración de mercado e índice de conversión, riesgos de crédito y renta – asumimos que todo es lineal, incluso cuando los datos sugieren lo contrario. Incluso nos gusta evocar explicaciones elaboradas para las tendencias y variaciones en los datos, incluso cuando son explicadas de modo más adecuado por variación natural o aleatoria.
Y, tristemente, acomodamos nuestros sesgos mientras procesamos los datos.
Inclusión de la IA en el flujo de trabajo
Necesitamos evolucionar más e incluir la IA en el flujo de trabajo como procesador principal de los datos. Para decisiones de rutina que dependan solamente de los datos estructurados, obtenemos los mejores resultados cuando delegamos las decisiones a la IA, que es menos propensa resultados al sesgo cognitivo de los humanos. (Hay un riesgo muy real en la utilización de datos sesgados, que pueden llevar a la IA a encontrar relaciones ilusorias y que sean tendenciosas. Debemos asegurarnos de comprender como los datos son generados, además de como son utilizados) La IA puede ser entrenada para encontrar segmentos en la población que mejor explique la variación en niveles de granulación fina, aunque sea contraintuitivo para nuestra percepción humana. La IA no tiene dificultad para manejar millares – o incluso millones – de agrupamientos. Además, la IA está más que a gusto para trabajar con relaciones no lineales, sean exponensiales, leyes de potencia, series geométricas, distribuciones binomiales u otros.
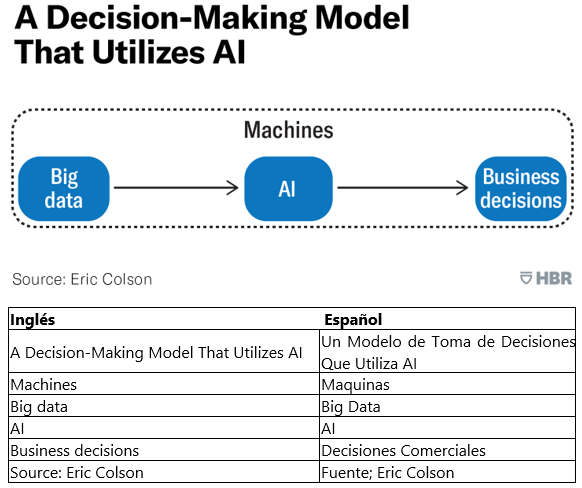
Este flujo de trabajo aprovecha mejor la información contenida en los datos, es más coherente y objetivo en sus decisiones y capaz de determinar mejor cual es el director de creación más eficaz, cual es el nivel ideal de existencias a establecer o cuales las inversiones financieras a efectuar.
Aunque los humanos sean removidos de este flujo de trabajo, es importante observar que sólo la automatización no es el objetivo de un flujo de trabajo guiado por IA. De hecho, él puede reducir costos. Pero eso es sólo un beneficio más. El valor de la IA está en tomar decisiones mejores que las decisiones humanas tomadas sin auxilio. Esto crea un salto cualitativo de mejoría en la eficiencia y abre espacio para nuevas posibilidades.
Aprovechamiento de la IA y de procesadores humanos en el flujo de trabajo
Remover a los humanos de los flujos de trabajo que implican solo el procesamiento de datos estructurados no significa que los humanos se tornan obsoletos. Hay muchas decisiones empresariales que dependen de más que solamente datos estructurados. Visiones de negocio, estrategias empresariales, valores institucionales y dinámicas de mercado son ejemplos de informaciones que solamente están disponibles en nuestra mente y son transmitidas a través de la cultura y de otras formas de comunicación no digital. Son informaciones inaccesibles a la IA es extremadamente relevante para las decisiones empresariales.
Por ejemplo, puede ser que la IA determine objetivamente los niveles correctos de existencias para maximizar las ganancias. Sin embargo, en un ambiente competitivo la empresa podría optar por niveles más altos de existencias con el fin de proporcionar una experiencia mejor a los clientes, aún a costa de las ganancias. En otros casos, puede ser que la IA determine que, de las opciones disponibles en la empresa, invertir más recursos financieros en marketing traerá mayor retorno sobre la inversión. Sin embargo, la empresa podrá preferir moderar el crecimiento a fin de mantener las normas de calidad. La información adicional disponible para los humanos en la forma de estrategia, valores y condiciones de mercado pueden justificar un desvío de la racionalidad objetiva de la IA. En estos casos, la IA puede ser utilizada para generar posibilidades, dentro de las cuales los humanos podrían elegir la mejor alternativa, considerando la información adicional a la que tengan acceso. La orden de ejecución de estos flujos de trabajo es especifica para cada caso. A veces, la IA es lo primero para reducir la carga de trabajo a los humanos. En otros casos podría haber interacción entre la IA y el procesamiento humano.

La clave es que no haya interferencia directa de los humanos con los datos, pero si con las posibilidades producidas por el procesamiento de los datos ejecutado por la IA. Valores, estrategia y cultura son nuestras maneras de conciliar nuestras decisiones con la racionalidad objetiva. Esto trae mejores resultados cuando es hecho de forma explícita y totalmente informada. Al aprovechar tanto a los humanos como a la IA, podemos tomar decisiones mejores que al usar sólo una de las dos.
La próxima fase de la evolución
Pasar de “guiado por datos” a “guiado por IA” será la próxima fase de nuestra evolución. Asimilar la IA en nuestros flujos de trabajo proporciona un mejor procesamiento de datos estructurados y permite que los humanos contribuyan de formas complementarias.
Es improbable que esa evolución ocurra dentro de una sola organización, del mismo modo que la selección natural no ocurre en los individuos. En cambio, se trata de un proceso de selección que opera en una población. El índice de supervivencia será mas alto entre las organizaciones más eficientes. Considerando que es difícil que las empresas maduras se adapten a los cambios en el ambiente, sospecho que veremos el surgimiento de nuevas empresas que asimilarán tanto la IA como las contribuciones humanas desde el principio, incorporándolas nativamente en sus flujos de trabajo.
Eric Colson, autor de este contenido es el Director de Algoritmos de Stitch Fix. Su cargo anterior fue el de Vicepresidente de Ciencia e Ingeniería en Netflix.
Babel-Team, Strategic Solutions for Digital Innovation, seleccionó, tradujo, comentó y publicó el contenido original de Colson, Eric.
Previous Next